为什么你的AI总是那么笨?(此为先导,后必详述)
AI-摘要
Chat GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
本文最后更新于 2025-11-10,墨迹未干时,知识正鲜活。随着时间推移,文章部分内容可能需要重新着墨,请您谅解。Contact
序
其实大致就两个方向分析,用户自己不会用以及服务商搞猫腻。
服务商
先说服务商,经常用GPT官网的人应该有这种感觉:明明是同一个模型,为什么有时候就很聪明,一下子就能得出想要的结果,而有些时候简直蠢得没法看。这就要提到OpenAI在官网插的一堆遥测干扰了,据我实测,每当有新模型发布,或者每当OpenAI的服务快饱和的时候,老模型就会降智,说的专业点就是服务降级,把原先老模型的算力多分点给新模型,这样大家就会觉得新模型有质的飞跃,排行榜上的排名就高。本来冲榜不违法,你冲榜的时候降智那我就去用API,反正API不会降智,但是现在OpenAI跟疯了一样,只要你登录的IP风控高,就把你的账号服务降级,降级后的o1模型甚至不如原先的4o mini,Pro用户也不能幸免。
接下来说一下怎么看有没有被服务降级,打开官网https://chatgpt.com 并登录你的账号后,打开F12调试,然后随便问一个问题,回答的时候打开network并查询requirements请求,请求体里有一个工作量证明(POW),里面的difficulty参数值就是你当前的服务质量,一般来说,大于五位就是没有降智。
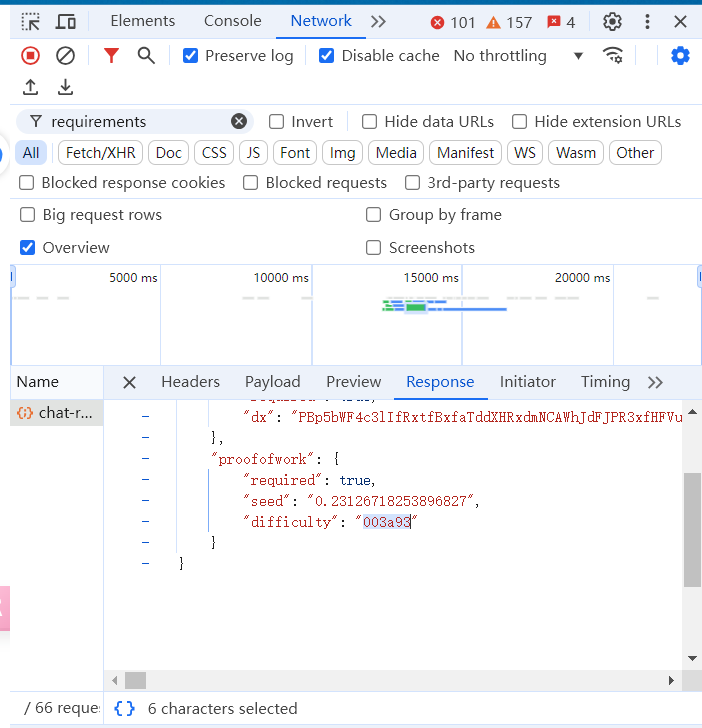
至于说已经被降智怎么处理,嗯,4o发个图然后秒断回答就行,这个方法不知道什么时候失效,及时行乐吧,或者转战API也行。
用户
这个说起来就多了,先写个引子吧。总的来说想要优化大模型回答主要从以下几个方面考虑:
- 模型参数:大杯中杯小杯,通俗来说就是训练的参数量,同一模型一般参数量越大越聪明,不同模型无法通过参数量比较,毕竟一岁的老虎爆杀十岁的狗。
- 提示词优化:老熟人了,也没什么好说的,系统学一下提示词工程就行,然后看一些优秀提示词,比如李继刚的
- RAG:涉及到向量和知识库,用向量模型去整理知识库,而且还能做到不更新模型只更新知识库,还算方便。不过我是不怎么用,一般都是小公司搞私有化知识库才用。载体一般是openwebui
- 其他杂七杂八的参数,比如温度,topp, topk, seed什么的,太过浩瀚,感觉穷极一生也学不完,学点常用的得了。
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 JackLee
阅读建议


评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果