LLM API使用场景示例
本文最后更新于 2025-11-10,墨迹未干时,知识正鲜活。随着时间推移,文章部分内容可能需要重新着墨,请您谅解。Contact
LLM API使用场景示例
前言:AI的应用其实和传统互联网技术产品的应用差不多,大致是两种方式——官网使用和API调用,二者区别可以简要概括为:官网是人工交互,用户导向;而 API 是批处理、互联式,开发者导向。二者应用场景不一样。
下面会列举一些简单的API应用场景示例,简单到你只需要选择一个Client客户端,填入你的API接口地址和鉴权秘钥即可使用,实际上现在AI相关技术发展迭代速度相当快,基础技术也越来越完善(RAG,MCP, Workflow等等),如果希望更加深入地使用API,建议阅读这份基础手册:https://apiai.apifox.cn/api-162417537
PS:本文有时间会持续更新新的场景示例,同时博客内的 AI TAG 也会更新AI相关技术与开源项目。
一、在 Cherry Studio 中使用
1. 下载 Cherry Studio
2. 配置
首先获取API Key 主要有三种获取途径:官方,API中转站,以及AI聚合平台。- “官方”指的就是你直接在OpenAI, Google, Claude和Deepseek等AI公司的API站点购买,比如:OpenAI的 https://platform.openai.com, Google的 https://console.cloud.google.com, Deepseek的 https://platform.deepseek.com 等。
- “AI聚合平台” 指的是Poe, Siliconflow, Openrouter这样将许多系列的AI模型聚合到一个站点的平台,通过发售积分或点数来统一计价标准,用户充值的时候得到对应的积分,消费时则根据模型的权重和单价来计费。这整个过程类似于超市里的混合糖果,将不同单价的糖果混合在一起售卖,最后标价的时候按照不同价格的糖果的单价和权重来计费。
- “API中转站"指的则是利用One API、New API等AI模型接口管理与分发系统,将不同API请求格式的大模型转为统一格式调用(大部分情况下是OpenAI通用格式)的站点,因为API站的LLM API格式都被统一为OpenAI格式,因此做到兼容OpenAI官方SDK库及大多数开源LLM项目。
接着点击左下角的设置,在模型服务中选择【OpenAI】(当然其他的服务也可以配置,只要接口地址和密钥正确就可以调用)
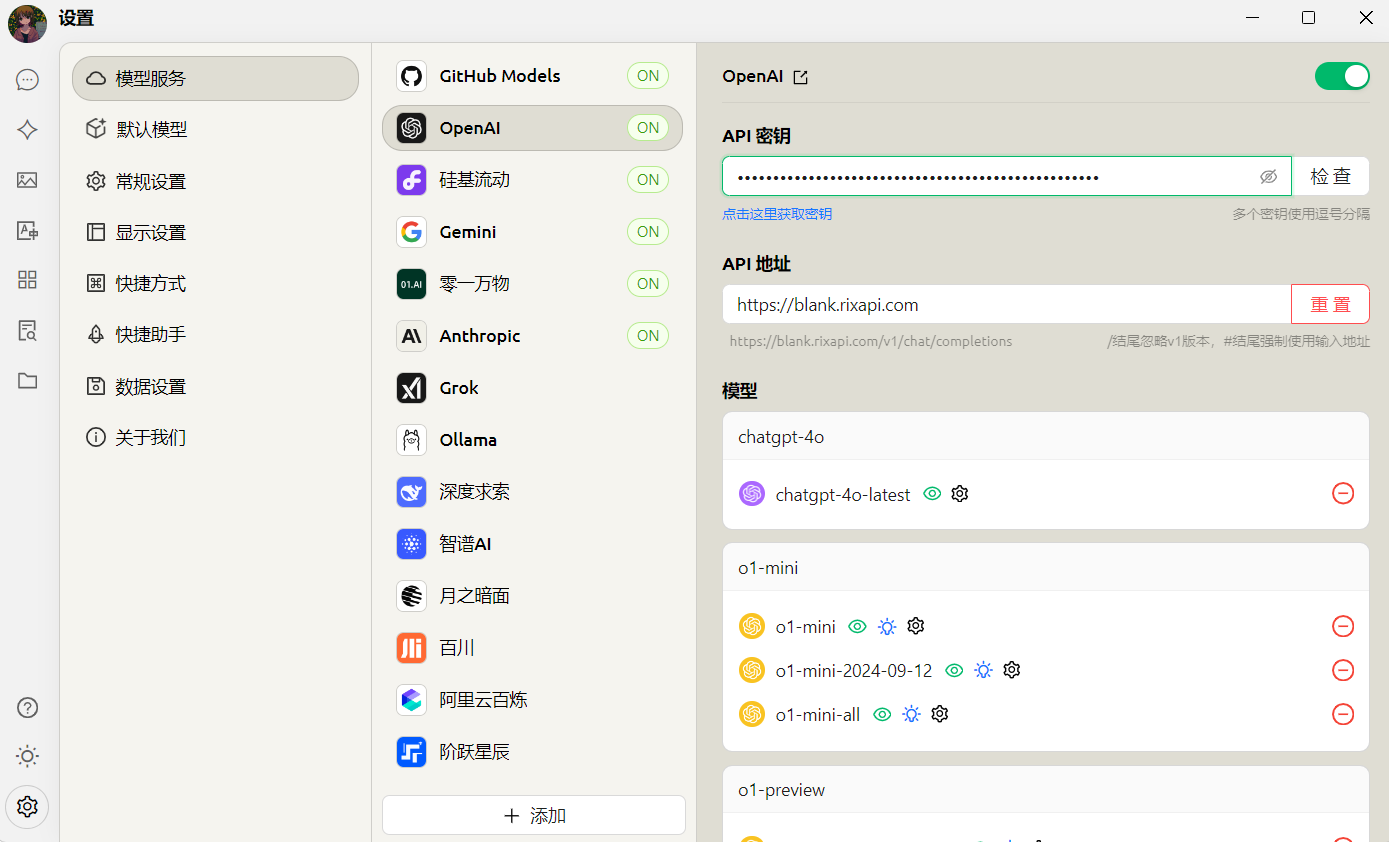
接着输入API秘钥和API地址(Baseurl),然后可以点击“管理模型”来增减模型,目前CherryStudio已经支持通过/models来获取模型列表(仅限OpenAI格式),因此即使不是OpenAI公司的模型,只要接口格式是OpenAI格式并且模型名与服务端对应得上,就可以一键获取模型并调用。
3. 模型服务使用
3.1 使用语言模型服务聊天
- 点击左侧菜单栏的“对话”按钮
- 在输入框内输入文字即可开始聊天
- 可以选择顶部菜单中的模型名字切换模型
3.2 使用嵌入模型服务创建知识库并使用
3.2.1 创建知识库
- 知识库入口:在 CherryStudio左侧工具栏,点击知识库图标,即可进入管理页面;
- 添加知识库:点击添加,开始创建知识库;
- 命名:输入知识库的名称并添加嵌入模型,以 bge-m3为例,即可完成创建。
3.2.2 添加文件并向量化
- 添加文件:点击添加文件的按钮,打开文件选择;
- 选择文件:选择支持的文件格式,如 pdf,docx,pptx,xlsx,txt,md,mdx 等,并打开;
- 向量化:系统会自动进行向量化处理,当显示完成时(绿色✓),代表向量化已完成。
3.2.3 添加多种来源的数据
CherryStudio 支持多种添加数据的方式:
- 文件夹目录:可以添加整个文件夹目录,该目录下支持格式的文件会被自动向量化;
- 网址链接:支持网址 url,如https://docs.siliconflow.cn/introduction;
- 站点地图:支持 xml 格式的站点地图,如https://docs.siliconflow.cn/sitemap.xml;
- 纯文本笔记:支持输入纯文本的自定义内容。
3.2.4 搜索知识库
当文件等资料向量化完成后,即可进行查询:
- 点击页面下方的搜索知识库按钮;
- 输入查询的内容;
- 呈现搜索的结果;
- 并显示该条结果的匹配分数。
3.2.5 对话中引用知识库生成回复
- 创建一个新的话题,在对话工具栏中,点击知识库,会展开已经创建的知识库列表,选择需要引用的知识库;
- 输入并发送问题,模型即返回通过检索结果生成的答案 ;
- 同时,引用的数据来源会附在答案下方,可快捷查看源文件。
二、在 NextChat 中使用
-
获取API key
-
随便找一个NextChat网页端,自己部署或用我的魔改版都行:
https://neat-chat.vercel.app/点击页面左下角的“设置”按钮,找到其中的“自定义接口”(
Custom Endpoint)选项并开启。然后填入参数:
- 接口地址(
Endpoint或BaseUrl): 默认是/api/openai,修改为https://API站地址/v1/chat/completions - API Key: 输入“ API 密钥页签 ”生成的 API Key
PS: 以上两个参数是必填项,如果使用的是非官方API,需要带https://和路径,/v1/chat/completions 是 标准完整OpenAI接口路径,但某些情境下不需要使用完整路径,使用v1路径即可。
- 此外nextchat中还支持自定义模型名和用webdav同步保存数据,只要模型接口兼容了OpenAI格式,就可以通过自定义模型名调用特定模型,比如将Dify中的agent接入new-api后通过自定义模型名调用。
三、沉浸式翻译中使用
首先安装沉浸式翻译扩展
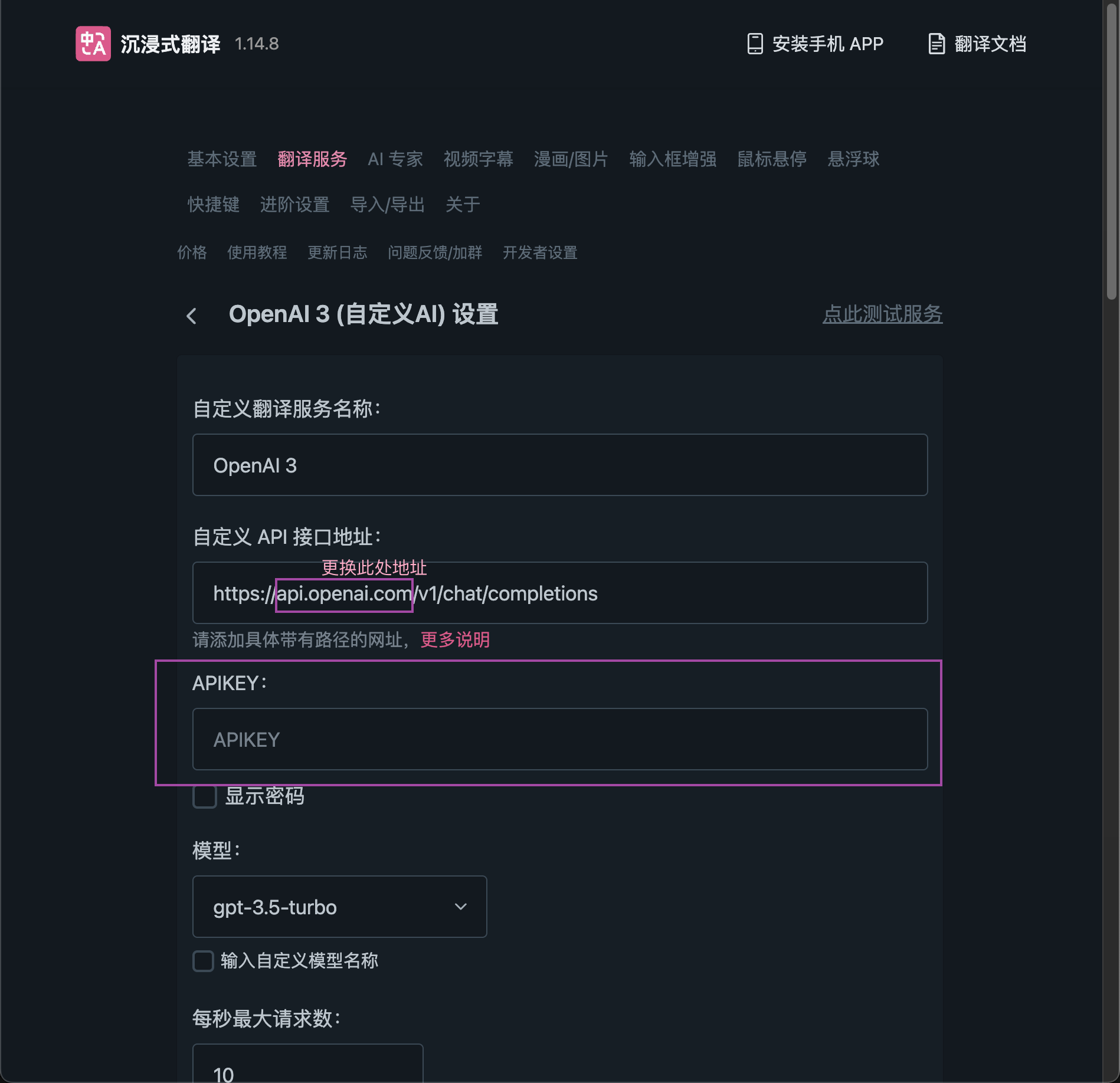
API接口地址填写 https://API地址/v1/chat/completions
API Key填获取的API KEY即可
PS:沉浸式翻译需要考虑API的 RPM(每分钟请求数)和 TPM(每分钟tokens 数)等参数的限制,沉浸式翻译这种高频低token的调用方式不适合所有LLM模型,因此综合考虑翻译效果、翻译速度和价格,最合适沉浸式翻译的LLM模型是gpt4o-mini, gpt4o, 如果需要更好的高token翻译任务,则可以使用deepseek r1, gemini exp, o1 mini等模型。
四、 chatgpt-web-midjourney-proxy中使用
我搭建的成品:https://www.273299033.xyz/
流程:设置-服务端-填入openai接口地址和key