论如何利用AI IDE更加优雅地辅助文字工作之“二十大报告中'坚持'一词双语语料的提取”
本文最后更新于 2025-11-10,墨迹未干时,知识正鲜活。随着时间推移,文章部分内容可能需要重新着墨,请您谅解。Contact
论如何利用AI IDE更加优雅地辅助文字工作之“二十大报告中'坚持'一词双语语料的提取”
引言
要提取出二十大报告双语材料中包含“坚持”一词的语料,第一反应当然是直接在Word里Ctrl F查找,但是此法有一弊——无法提取,即只能一一查找/替换,却无法批量提取出来,那么我们就得换换思路:
方案一:直接把报告全文丢给支持超长上下文的AI(如Gemini),让它负责提取,但是实测上下文过长,模型幻觉太严重了,即使我已经事先用Word自带的替换功能为它用###标记出所有"坚持"的位置,它仍然出现大量的幻觉,遂弃此方案。
方案二:既然全文太长,那么拆分一下在以单次单任务的形式喂给Gemini,是不是可以呢?实测差不多需要分20份左右才能保证它的幻觉不影响输出,如果这份报告是标准的ABAB格式,那我就写个脚本批量切分或者以工作流的形式喂给AI了,可惜这份报告一段中文对应的英文段数是不确定的,或许可以用编码格式来区分,又或许可以喂给其他AI来切分,但是太麻烦了,而且引入更多的不稳定的变量来减小误差?怕是越搞越乱,弃之如鸡肋。
实操
最后之法:正所谓结构越简单越不容易出错,正则就是这样一个好东西,随便选一个AI IDE帮你编写、调试一下Python正则匹配脚本,这里我选的是Augment,主要是因为其足以匹敌Gemini的超长上下文和方便的权限设置,另外现在EA阶段所有用户免费不限量使用。
言归正传,脚本如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
提取二十大报告中包含"坚持"一词的句子
"""
import re
import os
def split_into_sentences(text):
"""
将文本分割成句子。
中文句子通常以句号、问号、感叹号结束,但也要考虑引号等情况。
"""
# 使用正则表达式分割句子
# 句子结束标志:句号、问号、感叹号,后面可能跟着引号、括号等
sentence_endings = r'([。!?\!\?][\"\'\]\)\}]?)'
sentences = re.split(sentence_endings, text)
# 重新组合句子和它们的结束符
result = []
for i in range(0, len(sentences), 2):
if i + 1 < len(sentences):
result.append(sentences[i] + sentences[i + 1])
else:
# 处理最后一个可能没有结束符的句子
result.append(sentences[i])
# 过滤空句子
return [s.strip() for s in result if s.strip()]
def extract_sentences_with_keyword(file_path, keyword):
"""
从文件中提取包含关键词的句子
"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 移除Markdown标记和英文部分(通常在中文段落后面)
# 这里简单处理,假设中英文是交替出现的
lines = content.split('\n')
chinese_content = ""
for line in lines:
# 跳过空行和英文行(简单判断,可能需要更复杂的逻辑)
if not line.strip() or (line.strip() and all(ord(c) < 128 for c in line.strip())):
continue
chinese_content += line + "\n"
# 分割成句子
sentences = split_into_sentences(chinese_content)
# 提取包含关键词的句子
keyword_sentences = []
for sentence in sentences:
if keyword in sentence:
# 移除可能的Markdown标记
clean_sentence = re.sub(r'[#*_`]', '', sentence)
keyword_sentences.append(clean_sentence)
return keyword_sentences
except Exception as e:
print(f"处理文件时出错: {e}")
return []
def save_results(sentences, output_file):
"""
将结果保存到文件
"""
try:
with open(output_file, 'w', encoding='utf-8') as file:
file.write(f"# 包含\"坚持\"一词的句子\n\n")
for i, sentence in enumerate(sentences, 1):
file.write(f"{i}. {sentence}\n\n")
print(f"结果已保存到 {output_file}")
except Exception as e:
print(f"保存结果时出错: {e}")
def main():
input_file = "中英双语二十大报告全文.md"
output_file = "坚持_sentences.md"
keyword = "坚持"
print(f"正在从 {input_file} 中提取包含\"{keyword}\"的句子...")
sentences = extract_sentences_with_keyword(input_file, keyword)
if sentences:
print(f"找到 {len(sentences)} 个包含\"{keyword}\"的句子")
save_results(sentences, output_file)
else:
print(f"未找到包含\"{keyword}\"的句子")
if __name__ == "__main__":
main()
打开终端运行一下:
PS C:\Users\Administrator\Documents\augment-projects\online-chat> python extract_jianchi_with_english.py
正在从 中英双语二十大报告全文.md 中提取包含"坚持"的句子及其英文翻译...
共提取到 148 对中英文段落
找到 90 个包含"坚持"的句子
结果已保存到 坚持_sentences_with_english.md
PS C:\Users\Administrator\Documents\augment-projects\online-chat>
PS C:\Users\Administrator\Documents\augment-projects\online-chat> dir .\坚持_sentences.md
目录: C:\Users\Administrator\Documents\augment-projects\online-chat
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2025/5/8 16:12 46437 坚持_sentences.md
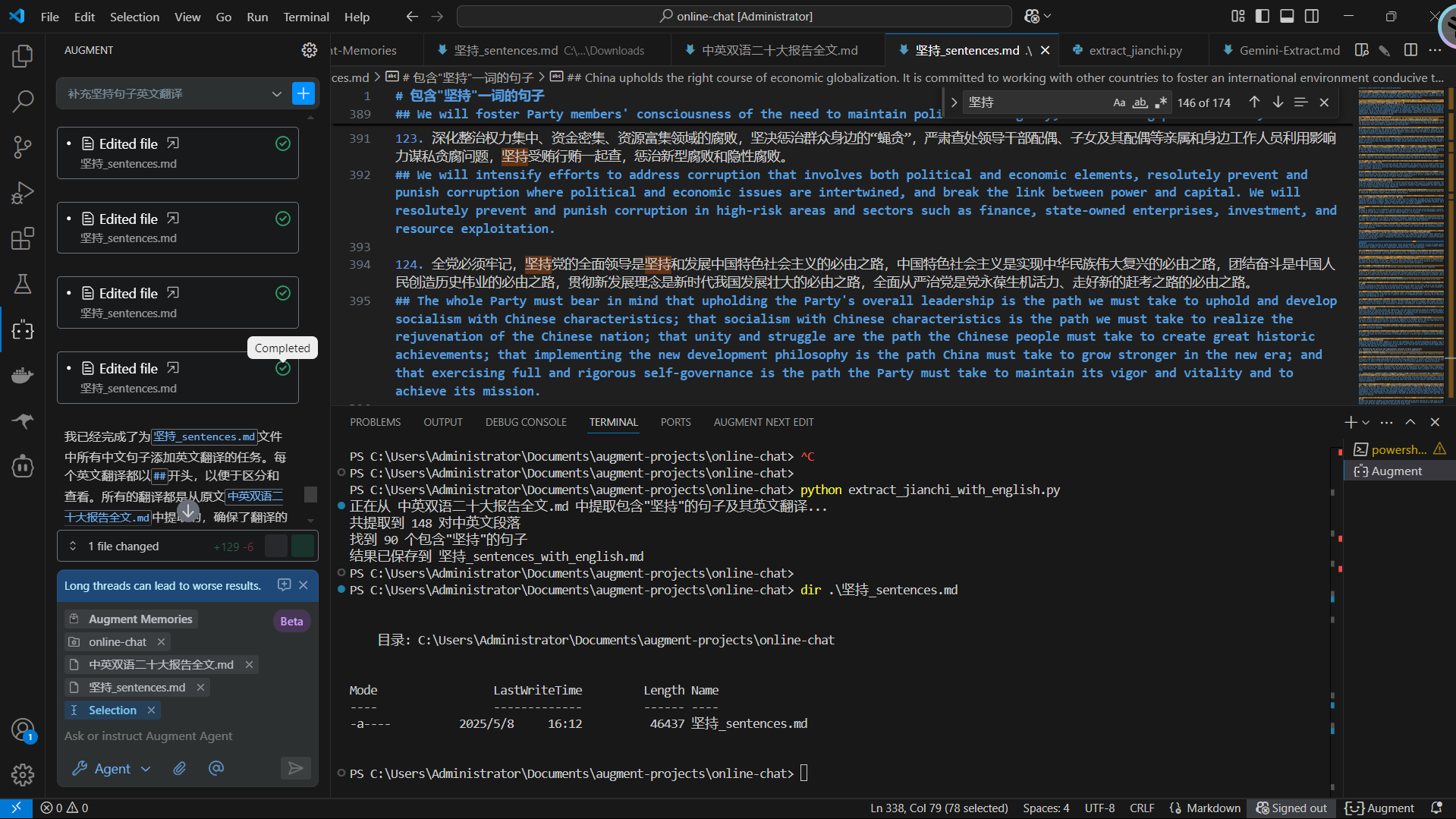
然后新的问题又来了:正则匹配筛选后的提取物中存在只提取了中文,对应的英文没有提取的情况,在修改脚本和求助Augment中果断选择使用Augment帮我匹配。把两份文档都开放给Augment,再把它温度调低、设置一个严格的提示词(降低幻觉概率),让它使用正则匹配后添加到脚本提取物中。
这时候就体现出AI IDE的好处了,如果是那种一问一答式的交互式AI调用方式的话,这一步你不但要上传两份大文件,而且AI输出的时候还需要再大量输出,而AI IDE这种调用方式就完全没有这个烦恼,开放读取和编辑权限后,它可以做到在已有的基础上进行增删,大大减少调用成本和被截断的风险。总而言之,一百七十三条,差不多处理了二十分钟完全处理完,即得到AI处理后的完整的原始语料。
原始语料:https://cloudpaste.itvoyager.us/file/jianchi-original-linguistical-data
反查
只是拿到AI处理后的原始语料还是不够的,因为从提取物到原始语料使用了一次大语言模型的"智",即引入了不稳定的变数,即使我已经降低了模型温度、植入了严格的提示词,并且选择了指令遵循性能好的IDE模型,它依旧是变数。所以这一步需要再写一个脚本,用AI处理后的原始语料去原报告反查,脚本如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
验证提取的句子是否与原文一致的脚本
用法: python verify_sentences.py
"""
import re
import os
import sys
def load_file(file_path):
"""加载文件内容"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except Exception as e:
print(f"无法读取文件 {file_path}: {e}")
sys.exit(1)
def extract_chinese_sentences(content):
"""从坚持_sentences.md中提取中文句子"""
sentences = []
lines = content.split('\n')
current_item_number = None
current_chinese_lines = []
for line in lines:
# 跳过标题行和空行
if (line.startswith('#') and not line.startswith('##')) or not line.strip():
continue
# 如果是数字编号开头,这是一个新条目的开始
match = re.match(r'^(\d+)\.\s', line)
if match:
# 保存之前的条目
if current_chinese_lines:
chinese_text = ' '.join(current_chinese_lines)
if chinese_text.strip():
sentences.append({
'index': current_item_number,
'text': chinese_text.strip()
})
# 开始新条目
current_item_number = int(match.group(1))
current_chinese_lines = [line[line.find('.')+1:].strip()]
elif line.strip().startswith('##'):
# 英文翻译部分,跳过
continue
# 检查是否包含英文字母(简单判断是否为英文)
elif re.search(r'[a-zA-Z]', line) and len(re.findall(r'[\u4e00-\u9fff]', line)) < 5:
# 主要是英文内容,跳过
continue
elif current_chinese_lines:
# 继续当前条目的中文部分
current_chinese_lines.append(line.strip())
# 添加最后一个条目
if current_chinese_lines:
chinese_text = ' '.join(current_chinese_lines)
if chinese_text.strip():
sentences.append({
'index': current_item_number,
'text': chinese_text.strip()
})
return sentences
def verify_sentences(sentences, original_content):
"""验证句子是否在原文中存在"""
results = []
# 清理原文中的多余空格,便于比较
clean_original = re.sub(r'\s+', '', original_content)
for sentence_obj in sentences:
sentence_index = sentence_obj['index']
sentence_text = sentence_obj['text']
# 清理句子中的多余空格
clean_sentence = re.sub(r'\s+', '', sentence_text)
# 在原文中查找句子
found = clean_sentence in clean_original
# 如果没找到,尝试分段查找
if not found and len(clean_sentence) > 50:
# 将句子分成多个部分,每部分至少50个字符
parts = []
start = 0
min_part_length = 50
while start < len(clean_sentence):
end = min(start + 200, len(clean_sentence))
if end < len(clean_sentence):
# 找到一个合适的断句点
while end > start + min_part_length and not (
clean_sentence[end] in '。,;!?' or
clean_sentence[end-1] in '。,;!?'):
end -= 1
parts.append(clean_sentence[start:end])
start = end
# 检查每个部分是否都在原文中
all_parts_found = True
missing_parts = []
for part in parts:
if part and len(part) >= min_part_length and part not in clean_original:
all_parts_found = False
missing_parts.append(part)
found = all_parts_found and len(parts) > 0
# 记录结果
results.append({
'index': sentence_index,
'sentence': sentence_text,
'found': found,
'length': len(clean_sentence)
})
# 按索引排序
results.sort(key=lambda x: x['index'])
return results
def generate_report(results):
"""生成验证报告"""
total = len(results)
found = sum(1 for r in results if r['found'])
not_found = total - found
report = []
report.append("# 句子验证报告")
report.append(f"\n## 摘要")
report.append(f"- 总句子数: {total}")
report.append(f"- 在原文中找到: {found}")
report.append(f"- 未在原文中找到: {not_found}")
report.append(f"- 准确率: {found/total*100:.2f}%\n")
if not_found > 0:
report.append("## 未找到的句子")
for r in results:
if not r['found']:
# 显示句子长度,帮助分析问题
report.append(f"{r['index']}. 长度: {r['length']} 字符")
report.append(f" {r['sentence']}")
report.append("")
report.append("## 详细结果")
for r in results:
status = "✓ 验证通过" if r['found'] else "✗ 未找到"
report.append(f"{r['index']}. {status} (长度: {r['length']} 字符)")
# 只显示句子的前100个字符
preview = r['sentence'][:100] + ('...' if len(r['sentence']) > 100 else '')
report.append(f" {preview}\n")
# 添加建议
report.append("## 分析与建议")
report.append("1. 验证脚本通过去除空格后进行全文匹配,可能会有一定的误差")
report.append("2. 对于长句子,脚本会尝试分段匹配,但仍可能存在误判")
report.append("3. 建议手动检查未找到的句子,特别是较长的句子")
report.append("4. 如果句子确实在原文中存在但未被检测到,可能是因为句子被分割或有细微差异")
# 添加英文内容过滤说明
report.append("5. 脚本已尝试过滤英文内容,但可能仍有一些英文内容被包含在提取的句子中")
report.append("6. 对于包含大量英文的句子,建议手动检查原文")
return "\n".join(report)
def main():
# 文件路径
extracted_file = "坚持_sentences.md"
original_file = "中英双语二十大报告全文.md"
# 检查文件是否存在
if not os.path.exists(extracted_file):
print(f"错误: 文件 {extracted_file} 不存在")
sys.exit(1)
if not os.path.exists(original_file):
print(f"错误: 文件 {original_file} 不存在")
sys.exit(1)
# 加载文件内容
extracted_content = load_file(extracted_file)
original_content = load_file(original_file)
# 提取句子
sentences = extract_chinese_sentences(extracted_content)
print(f"从 {extracted_file} 中提取了 {len(sentences)} 个中文句子")
# 验证句子
results = verify_sentences(sentences, original_content)
# 统计结果
total = len(results)
found = sum(1 for r in results if r['found'])
not_found = total - found
accuracy = found/total*100 if total > 0 else 0
print(f"验证结果: 总计 {total} 个句子, 找到 {found} 个, 未找到 {not_found} 个, 准确率: {accuracy:.2f}%")
# 生成报告
report = generate_report(results)
# 保存报告
report_file = "验证报告.md"
with open(report_file, 'w', encoding='utf-8') as f:
f.write(report)
# 如果有未找到的句子,输出到单独的文件
if not_found > 0:
unmatched_content = []
unmatched_content.append("# 未匹配到的句子\n")
unmatched_content.append("以下句子在原文中未找到匹配:\n")
for r in results:
if not r['found']:
unmatched_content.append(f"## 句子 {r['index']}\n")
unmatched_content.append(f"长度: {r['length']} 字符\n")
unmatched_content.append(f"{r['sentence']}\n\n")
# 保存未匹配句子到单独文件
unmatched_file = "unmatched.md"
with open(unmatched_file, 'w', encoding='utf-8') as f:
f.write("\n".join(unmatched_content))
print(f"验证完成,详细报告已保存到 {report_file}")
print(f"未匹配的句子已保存到 {unmatched_file}")
print("\n注意: 有些句子未在原文中找到,这可能是因为:")
print("1. 句子在提取过程中被合并或分割")
print("2. 句子中包含了英文内容")
print("3. 句子中有细微的差异(如标点符号、空格等)")
else:
print(f"验证完成,详细报告已保存到 {report_file}")
print("所有句子都在原文中找到匹配!")
if __name__ == "__main__":
main()
处理结果:https://cloudpaste.itvoyager.us/file/jianchi-reverse-check
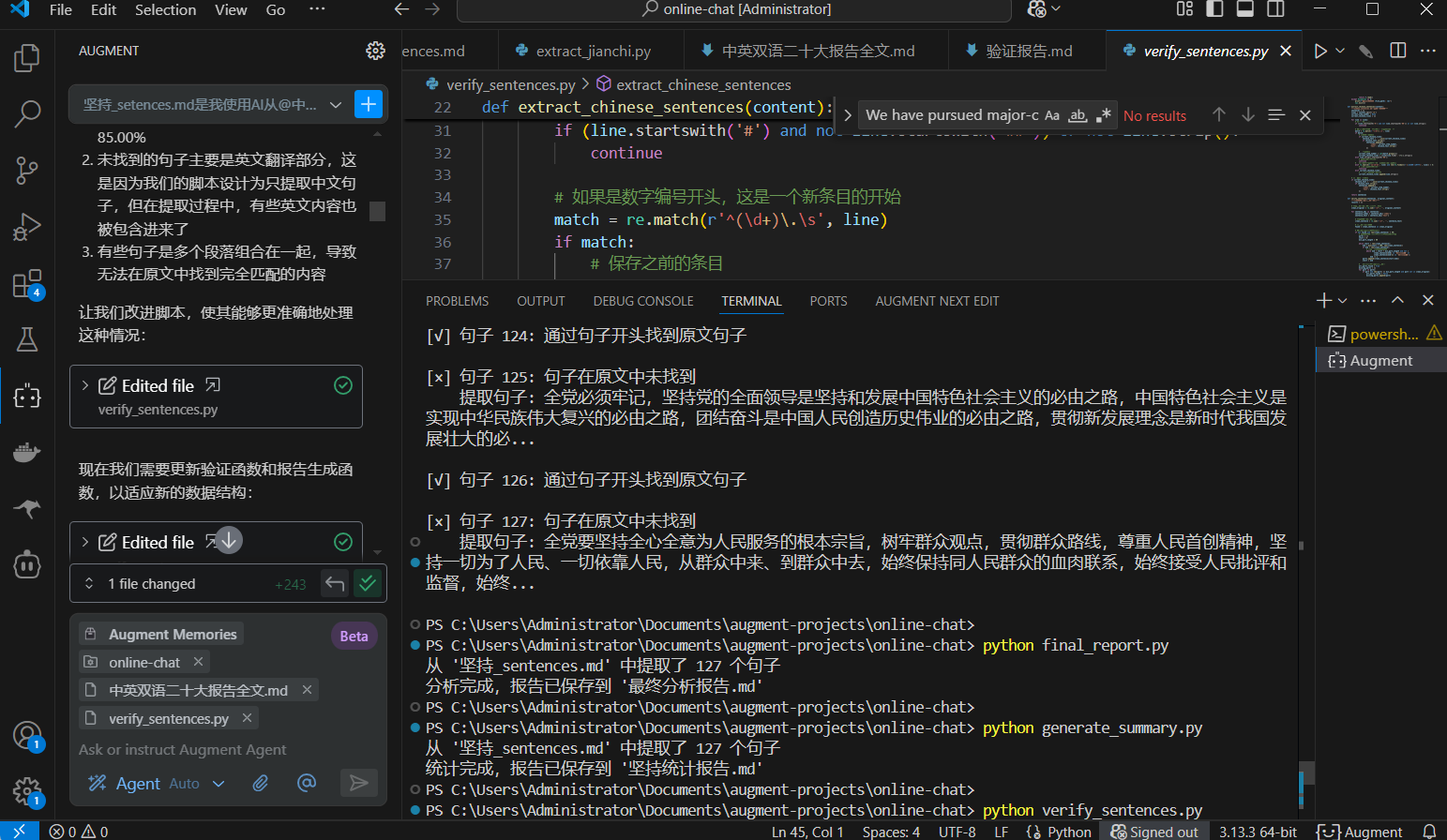
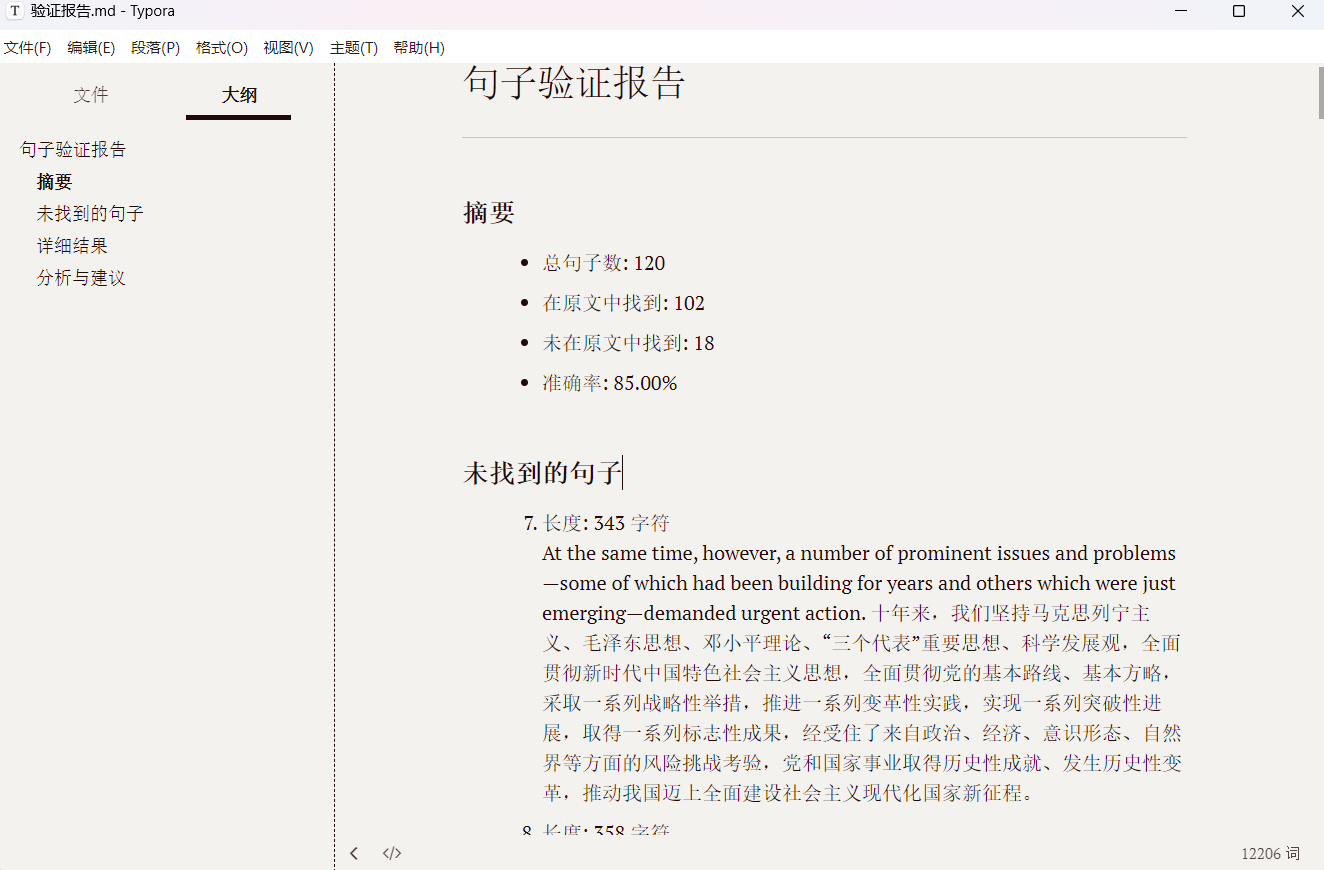
现在开始看验证结果,没匹配到的一共是18 句,数量已经很少了,接下来可以人工筛查,也可以扔给Gemini,反正现在数量已经少到幻觉的概率极低,我选择人工看一遍,有一些发现:未匹配的所有句子都在原报告中客观存在,未经篡改,之所以匹配失败是因为Augment在提取匹配,生成原始语料的时候每一段的第二局都有小概率出现一个"_"下划线(如下图),所以脚本无法匹配这个下划线导致误判。总的来说,语料准确度是没问题了,接下来统计。

统计
下面我们开始统计:
总共173个“坚持”,其中存在一句内包含多个“坚持”且间隔很短的情况,并且存在"省略","意译","合句"等情况,总之这一步想要用功能固定格式死板的脚本已经不现实了。
但人工一个一个识别又非我初衷,那么要想办法偷懒,我首先想到反正它翻译情况没多少种,不如先把出现频率高的先识别后剔除,然后剩余的语料大大减少,感觉直接扔给Gemini就没什么问题了,但可以剔除的也要考虑有可能被剔除的词在句中不译为”坚持“,那么还是要对被剔除的进行审查,周末快结束了,所以想进一步偷懒就只能借助AI了,在尝试了各种AI IDE后( Cursor, Augment和Roo Code),我发现或许是编程方面的预设加的有点多,导致通过IDE调用的模型别说处理翻译任务了,连给它确切的指令和目标,让它识别已经翻译好的文本都费劲。遂放弃,转向一问一答的无预设影响的调用方式来完成任务。此处我选择谷歌的AI Studio,提示词:
这是二十大报告的中文和对应的英译合订本,我需要你从这些语料中逐句甄别”坚持“一词在每一句是如何英译的,注意考虑意译或者省略的情况,如果无法确定的情况,请标注无法识别,不得子虚乌有凭空捏造含义或对原始语料进行任何程度的篡改。总共有173个坚持,请不要凭空捏造。
最终你的输出格式应当符合以下格式:
1.译为uphold....
2.意译为....
3.省略....
4.无法识别
....
汇总:”坚持“一词有...种翻译方法,其中uphold占......,commit占....,意译情况占...
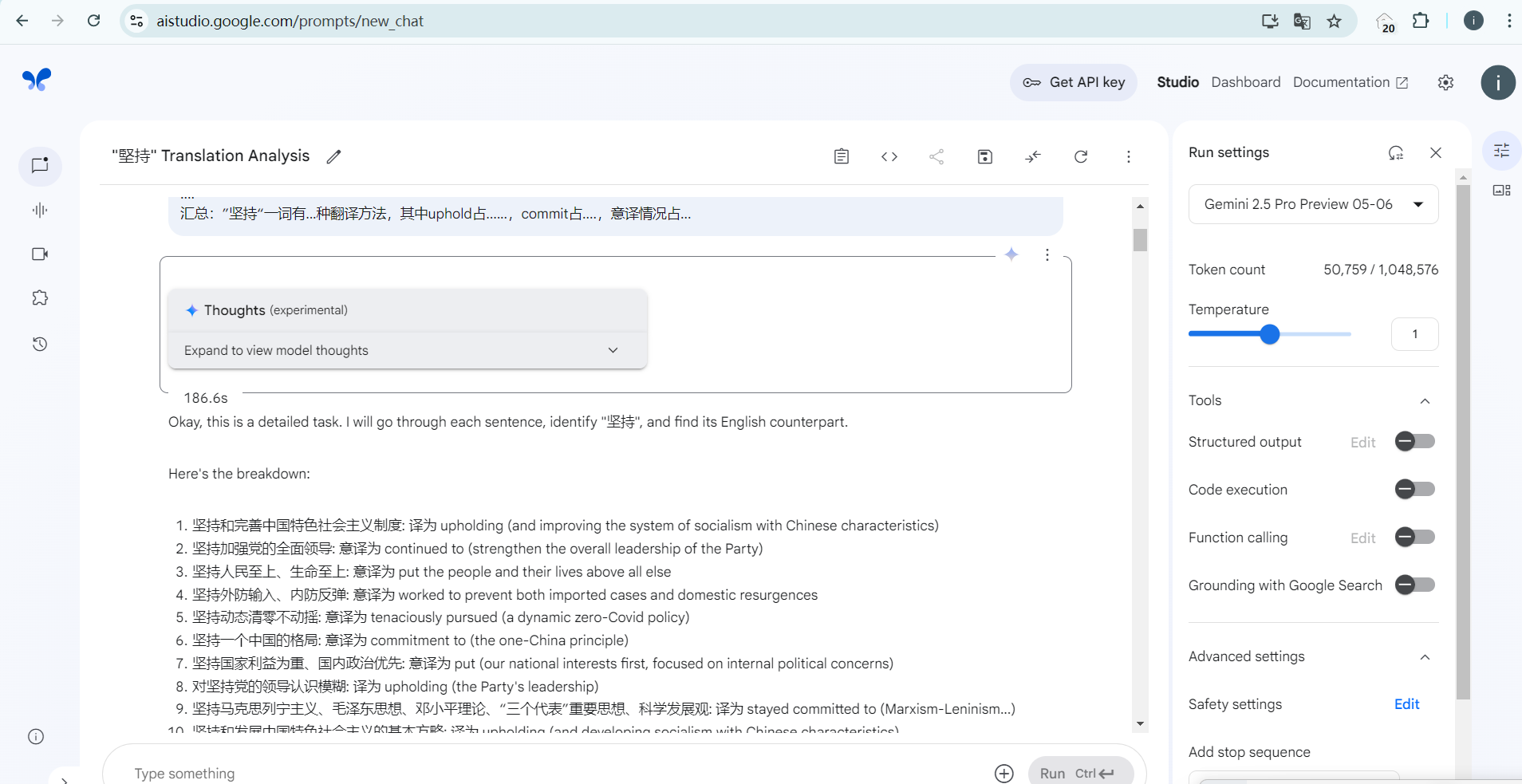
输出结果我放在我的R2对象存储中:https://cloudpaste.itvoyager.us/file/jianchi-analysis
emm,反正结果依然不太理想,切分语料后效果或许会更好,但是没时间了。